데이터 정규화 모델링
2024. 7. 11. 21:52ㆍ데이터베이스
반응형
이 글은 '관계형 데이터 모델링 프리미엄 가이드 (이론과 실무를 겸비한 최고의 전략서)'를 보고 학습한 내용을 정리한 글입니다.
- 데이터 모델링이 어려운 이유?
- 모델링 이론 외에 알아야 하는 분야의 폭이 넓기 때문
- 데이터의 본질(추상적인 개념), DBMS의 구체적인 특징과 기능까지 모두 알아야 함
- 데이터 관점과 성능 관점 모두 지식을 습득해야 함
- 사실상 정답이 없음
- 좋은 모델은?
- 단순하고 명확한 모델
- 데이터 무결성이 보장되는 모델
- 성능과 대척점에 있는 경우도 있음
- 본질적으로 중복을 줄이는 것
2장. 데이터 모델링 기본 개념
- 관계형 데이터 모델
- 함수 종속에 의해 정규화된 모델이 관계형 모델이다.

관계형 데이터베이스의 릴레이션
- 함수 종속에 의해 정규화된 모델이 관계형 모델이다.
- 무결성(Integrity)
- 흠이 없이 온전함
- 데이터 값이 정확한 상태
- 정합성
- 데이터가 서로 모순이 없이 일관되게 일치해야 한다는 의미
- 무결성과는 조금 다름
- 엔터티 무결성
- 엔티티에 존재하는 모든 인스턴스는 고유해야 하며 대표 속성에는 NULL을 가지면 안된다
- 참조 무결성
- 도메인 무결성
- 특정 속성 값은 동일한 범주의 값만 존재해야 한다
- 업무 무결성
- 다른 무결성에도 포함될 수 있는 무결성
- 범위가 넓어서 주로 application에서 처리
- ex) 주문 금액이 3만원이 넘으면 배송비 무료
- 이런 무결성을 어플리케이션 로직에서만 구현하는 경우가 있는데, 물리적으로 DBMS 차원에서 강제하는 것이 바람직하다
- (PK, Unique, FK, Check, Default, Data Type, NULL/NOT NULL, Trigger 등)
- 데이터베이스 라이프 사이클

- 요구사항 분석
- 데이터베이스에서 관리해야 하는 데이터를 도출하고 분석하는 단계
- 사용자의 의견을 최우선으로 따름 (현업 인터뷰)
- 개념 모델링
- 요구사항을 분석하고 난 후 도출되는 데이터 측면의 결과물
- 논리 모델링 단계
- 핵심 데이터를 포함한 모든 데이터를 대상으로 모델링을 수행하는 단계
- 단계에서 해야 할 가장 중요한 타스크는 정규화
- 물리 설계
- 도출된 여러 객체(테이블, 인텍스, 제약 등)를 생성하는 단계
- 인덱스 설계가 포함
- 파티셔닝 전략, 테이블 타입 등 고려
- 사이클에서, 정규화는 반드시 필수적으로 거쳐야 한다. 정규화가 끝나고 난 후에야 비로소 비정규형을 고려해볼 수 있다.
데이터 표준화
- 일정한 기준에 따라 통일하는 것
- 정의가 정확한 국어사전을 만드는 것은 아니므로 일관되도록 사용하게 하는 것이 중요함
- 사원번호와 직원번호가 혼용되어 사용되면 안됨
- 표준화의 출발은 단어를 정의하는 것
- 사원과 직원이 동일한 의미라면 한 단어만 채택
- 채택되지 않은 단어는 시스템적으로 사용되지 못하도록 막아야함
- employee 로 정했다면 단축명도 정하기 (EMP)
- 특정한 날짜를 의미할때는 일자를 사용한다
- 시분초까지 의미할때는 일시를 사용
- 이같은 속성을 시스템에 등록해서 관리하는 것이 바람직하다
3장. 개념모델 & 논리모델 & 물리모델
개념모델
- 개념 모델은 데이터 모델
- 데이터를 가장 간단하게 표현하는 것이 개념 모델의 목적
- 개념 모델은 해당 주제 영역에 존재하는 핵심적인 중요 엔터티와 그 엔터티의 주요 속성이 도출된 모델
- 핵심적인 엔터티와 그 엔터티 사이의 관계를 도출한 것
- 엔터티를 어떻게 정의하느냐에 따라 속성과 관계가 달라짐
- 업무에서 핵심적인 데이터만을 대상으로 도출한 개념 모델은 힘들고 중요한 작업임
- 개념 모델에 존재하는 엔터티의 정의가 약간만 틀어져도 전체 시스템에 미치는 영향은 대단히 커질 수 있음
- 개념 모델은 논리 모델로 연결(Alignment)돼야 함
- 개념 모델은 업무를 분석하는 단계에서만 필요하고 논리 모델링 단계에서 다시 처음부터 모델링을 시작하는 것은 아님
- 개념 모델에 표현되었던 엔터티는 논리,물리 모델에도 그대로의 구조로 존재해야 함
- 엔터티가 개념 모델에는 없고 논리 모델에 바로 생겨서도 안 됨
- 개념 모델링 단계에서는 중요도가 떨어지는 엔티티는 도출시키지 않고 핵심 엔터티에 대한 정의와 모델구조에만 집중해야 함
- 요구 사항을 사용자나 IT담당자, 개발자 등이 이해할 수 있도록 데이터로 간결하게 표현하는 것이 개념 모댈의 목표임
- 데이터 모델을 문서나 언어로만 커뮤니케이션하는 것은 한계가 있음
- 상위 수준의 개념 모델일지라도 모형으로 존재해야 함
- 중요하고 핵심적인 엔터티와 그 엔터티 간의 관계에만 집중함으로써 고려 대상을 감소시키고 분석을 단순화시킴
- 가독성 측면에서 데이터(엔터티) 위주의 표현(표기법)이 사용돼야 함
- 해석에 띠라 의미가 달라지는 애매한 표현은 사용을 지양해야 함
- 개념 모델은 분석 단계에서 유용하게 사용됨
- 초기 분석 단계에서는 핵심적인 업무와 중요 데이터를 확인해야 함
- 개발 프로젝트에서 가장 중요한 산출물중의 하나가 데이터 모델임
- 데이터 모델링은 데이터 아키텍처를 구성하는 요소 중에 가장 중요한 부분
- 개념 모델링은 대체로 주제 영역별로 수행됨
- 현실적인 어려움 때문에 업무 영역별로 수행됨
요구 분석
- 데이터 모델링을 수행하는데 필요한 데이터 관점의 요구사항을 분석하는 타스크를 의미함
- 데이터 관점의 요구 사항은 어떤 업무를 하려면 어떤 데이터가 사용돼야 하는지,좋은 품질의 데이터를 보유하고 업무를 빠르게 수행하려면 데이타 구조를 어떻게 해야 하는지 등을 의미함
- 모델링을 수행하는 중에도 지속적으로 모델에 반영되므로 요구 사항을 모델링과 분리할 수 없음
- 논리 물리 모델링 중에도 요구 사항은 반영돼야 함
- 만약 모델링을 수행하기 전에 데이터 관점의 요구사항을 텍스트로 정리하면 요구 분석 타스크가 모델링과 분리될 수 있겠지만 일반적으로 인터뷰하면서 모델링을 수행하는 중에 데이터 요구 사항이 도출됨
- 요구 사항을 제대로 분석하려면 현재의 업무를 알아야 하고 추가되는 요구사항을 도출해야함
- 업무에서 사용되는 데이터를 분석하는 것은 현업 IT 담당자와의 인터뷰로부티 수행됨
- 모델링 프로젝트에서 이 타스크를 어떻게 진행하느냐에 따라 데이터 모델의 품질이 결정됨
- 현행 데이터를 잘아는 IT 담당자가 반드시 상세한 인터뷰를 수행해줘야 함
- 현행 데이터의 문제점과 개선점을 요구해야 하며, 향후 추가되거나 보완해야 하는 업무에 대해서도 데이터 관점에서 요구해야 함
정규형
- 정규화 하는 과정은 산 정상에 오르는 것, 비정규화는 하산하는 것
- 정상에 오르지 않고 하산하는 것은 말이 안됨 → 정규화 하지 않고 비정규화를 할 수 없음
- 정석은 정규화를 하는 것이고, [성능 요건]에 따라 적절한 비정규화를 하는 것
- 비정규화를 한다고 무조건 성능이 좋아지는 것이 아님
- 성능지표 측정 필요
- 그런데 다년간의 경험 상 종합적인 성능은 비정규형이 더 낮음
- 심각한 성능 문제가 아닌 이상 정규형 채택
- 정규화는 중복을 제거하는 것이 기본적인 원칙
- 정규화를 하는 이유는 중복 데이터를 제거하고 데이터 이상 현상(anomaly)을 최소화하는 것이지 조회를 편하게 하기 위한 것이 아님
- 쿼리가 복잡해지는 것은 당연함
1정규형
- 속성이 원자적이어야함
- 물리적으로 하나의 값인 것 포함해서 논리적으로도 하나의 값만 가져야 함 (다가속성)
- 주소 등의 복합속성 → 업무에 따라 모호함 (ex. 서울시 은평구 증산동 123-47번지)
- 복합속성은 무조건 분해하는 게 정규형의 해답이 아님
- 작업요건이 정규화보다 더 중요한 경우도 있음
- 시/구/동을 구분해서 사용해야할 요건이 있거나 자주 집계하면 분리하는 게 좋을수도
- 무작정 분리했다가 불편할 수도
- 년/월/일 도 마찬가지
- 보험코드, 계좌번호 등 내부적으로 여러 의미를 담고있는 코드도 엄격하게는 1정규형 위반으로 볼 수 있음
- 코드의 각 자릿수 위치마다 의미를 갖고 있다거나 (snowflake 류)
- 여튼 비즈니스적으로 여러 의미를 갖게 되는 속성
- 이런 경우에는 이런 속성을 관리하는 데이터를 따로 관리해야함
- application 단에서만 알고 있으면 안됨

2정규형
- 후보 식별자의 속성이 2개 이상일 때만 대상
- 동일한 중복 속성이 생기는 것에 주의
- 실무에서 주로 조인을 피하기 위해 상품명을 두 릴레이션에 동시에 두는 경우
3정규형
- 이행적 종속성과 관련
- A → C 이고 C → D 이면 A → D가 성립함
- C는 후보 식별자가 아닌 일반 속성
- C를 식별자로 하는 릴레이션을 추가해야 함

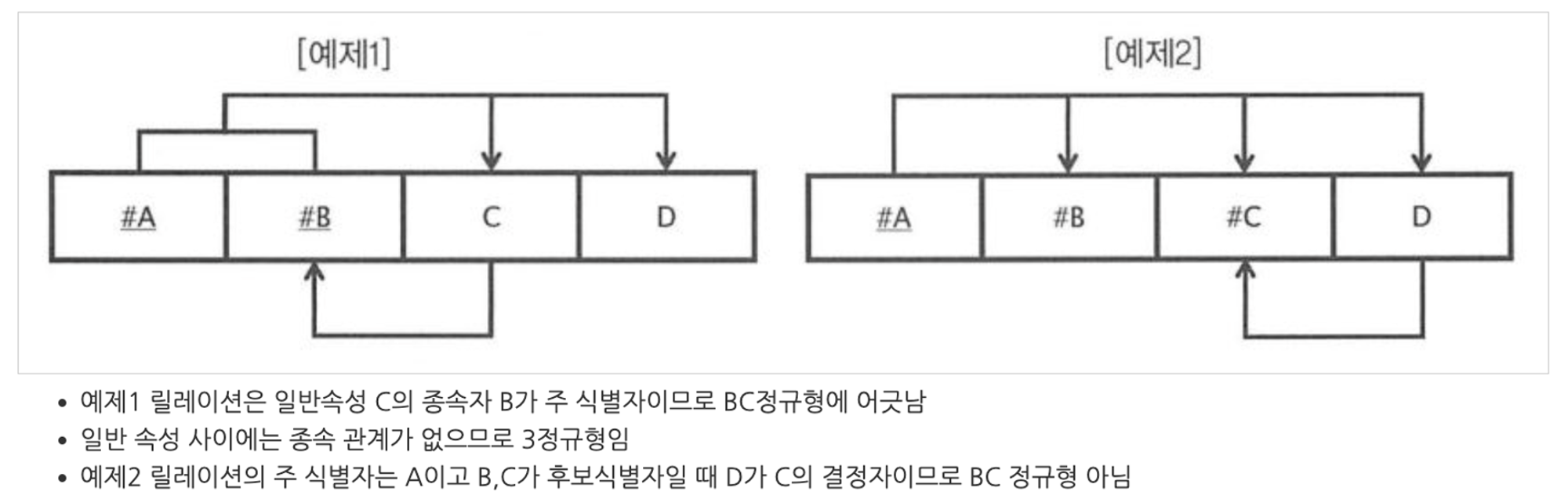
보이스코드(BC)정규형
- 실무에 적용하기 이상적인 단계
- 모든 속성의 결정자는 주 식별자여야 함
- 이와 함께 릴레이션에 존재하는 종속자가 후보 식별자이면 BC 정규형이 아님
4정규형 & 5정규형
- 과한 것 같음 (ㅎㅎ..)
- 지나치게 이론적이라서 실익이 없음
- 그래서 실무에서 사용하지 않기 위해서라도 알고 있어야 함ㅠ
반응형
'데이터베이스' 카테고리의 다른 글
| AWS RDS MySQL의 Handler 메트릭 모니터링 [PMM] (2) | 2024.11.12 |
|---|---|
| ProxySQL과 route53으로 MySQL 무중단 마이그레이션 및 업그레이드 (0) | 2024.11.11 |
| MySQL InnoDB 테이블 charset 변경시 주의사항 (0) | 2024.07.03 |
| mysql internal 및 도구 기록용 (0) | 2024.06.29 |
| MySQL 계정 관련 장애 사례 (0) | 2024.06.20 |