2022. 7. 1. 19:52ㆍ기타
개인 미니 게시판 프로젝트를 진행하고 있습니다.
최소한의 구동용으로 더미데이터가 필요해서 더미데이터를 넣는 방법을 찾아보게 되었습니다. mockaroo 라는 사이트에서 만들어주는 데이터가 아주 기깔나던데 무료회원은 1000건의 제한이 있어서 마음에 들지 않았습니다....
유저 1만 명, 게시글 5만 건, 댓글 10만 건 정도를 생각하고 있었어서 어떤 방법이 있을까 고민하다가, 파이썬의 faker와 csv 라이브러리를 이용해서 csv 파일을 만들고, mysql에서 지원하는 기능으로 csv를 바로 insert 하는 방법으로 더미데이터를 삽입했습니다.
아래는 하루동안 해봤던 삽질과 진행과정입니다.
from faker import Faker
import datetime
from dateutil.parser import parse
import csv
import pandas as pd
import numpy as np
import random
def random_dates(start, end, n):
start_u = start.value//10**9
end_u = end.value//10**9
return pd.to_datetime(np.random.randint(start_u, end_u, n), unit='s')
f=Faker("ko_KR")
### users.csv
user_file=open('users.csv','w',encoding='utf-8-sig',newline='')
writer=csv.writer(user_file)
start = pd.to_datetime('2020-01-01')
end = pd.to_datetime('2022-07-01')
user_data_num=10000
DATES=random_dates(start,end,user_data_num)
for i in range(user_data_num):
user_file_row=[i+1,f.email(), f.name(), f.profile().get('username'), "일반", DATES[i],DATES[i]]
writer.writerow(user_file_row)
user_file.close()
print('user done')
### post.csv
post_file=open('post.csv','w',encoding='utf-8-sig',newline='')
writer=csv.writer(post_file)
start = pd.to_datetime('2020-01-01')
end = pd.to_datetime('2022-07-01')
post_data_num=50000
DATES=random_dates(start,end,post_data_num)
for i in range(post_data_num):
post_file_row=[i+1,f.sentence(), f.text().replace('\n',' '), 0, random.randrange(1,3), random.randrange(1,user_data_num),DATES[i],DATES[i],0]
writer.writerow(post_file_row)
post_file.close()
print('post done')
### comment.csv
comment_file=open('comment.csv','w',encoding='utf-8-sig',newline='')
writer=csv.writer(comment_file)
start = pd.to_datetime('2020-01-01')
end = pd.to_datetime('2022-07-01')
comment_data_num=100000
DATES=random_dates(start,end,comment_data_num)
for i in range(comment_data_num):
comment_file_row=[i+1,random.randrange(1,post_data_num), random.randrange(1,user_data_num), f.paragraph().replace("\n",' '),DATES[i],DATES[i]]
writer.writerow(comment_file_row)
comment_file.close()
print('comment done')csv 파일 생성을 위해 작성한 python3 코드입니다. 널리 쓰일 코드는 아니라서 가독성과 객체지향성은 최소로 하고 돌아가기만 하면 된다는 생각으로 짜서 보기 힘드실 것 같네요 미리 사과의 말씀을 드립니다 -_-
핵심만 말씀드리자면, faker 라이브러리의 email(), profile(), text() 같은 함수들이 자동으로 랜덤 데이터를 뱉어줍니다. 이걸 배열로 만들어서 csv 파일에 쓰는 간단한 프로그램입니다.
혹시나 있을 저와 같은 분들을 위해 하나 말씀드리자면, 자동 생성되는 문자열 중 '\n' 이 포함된 문자열이 있습니다. 이걸 바로 csv 파일에 쓰게 되면 row 숫자가 잘 맞지 않게되어 데이터 쓰기가 힘들어집니다... replace()로 개행을 제거하고 사용하시는 것을 추천드립니다. 추천이 아니라 무조건 그렇게 해야 되더랍니다.. 저도 알고싶지 않았습니다....

대충 csv파일이 만들어진 것 같으면, workbench의 다음 과정을 통해 데이터를 삽입합니다.





저는 안됩니다.. 왜 안될까 하며 인코딩도 바꿔보고, 인코딩도 바꿔보고, 인코딩도 바꿔보고, 워크벤치 다른 버전도 몇개 깔아보고,,,,,, 울어도 보고 재부팅도 해봤습니다.
좀 더 찾아보니 m1 몬터레이에서 작동하는 workbench 8.0.29 버전은 csv파일 임포트가 안되는 이슈가 있다고 합니다.
그래서 어쩔 수 없이... cli에서 작업하기로 결정합니다.
도커에 mysql을 깔아서 쓰는지라 터미널로 접속을 시도합니다.
아, 그 전에 로컬에서 작업한 csv 파일을 옮겨줍니다.
문법은 :
docker cp ~/<csv-file-name>.csv <container-id>:/
여튼, 다시 터미널로 접속해봅니다.
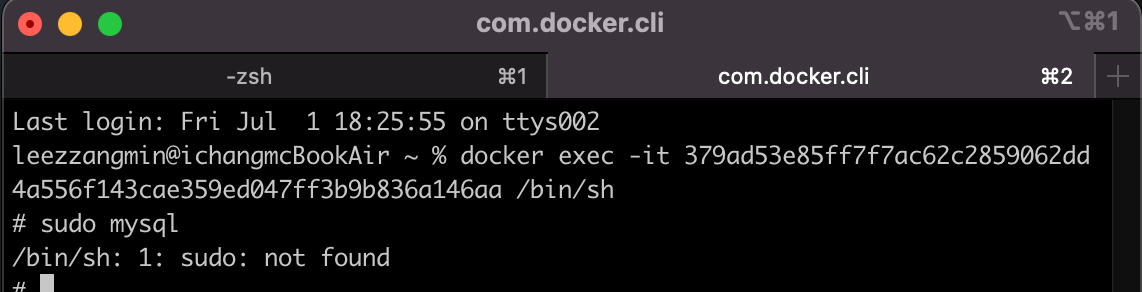
도커는 쓸때마다 여러가지 의미로 충격적입니다. sudo가 없다니..

대충 잘 접속해 줍니다.
그런 다음, 다음 명령어로 데이터를 삽입해 주기만 하면 끝입니다.
LOAD DATA LOCAL INFILE '/filename.csv' INTO TABLE tablename FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';
다음 글을 보고 해결해봅니다..
ERROR: Loading local data is disabled - this must be enabled on both the client and server sides
I don't understand the responses that others have provided to similar questions except for the most obvious ones, such as the one below: mysql> SET GLOBAL local_infile=1; Query OK, 0 rows affec...
stackoverflow.com
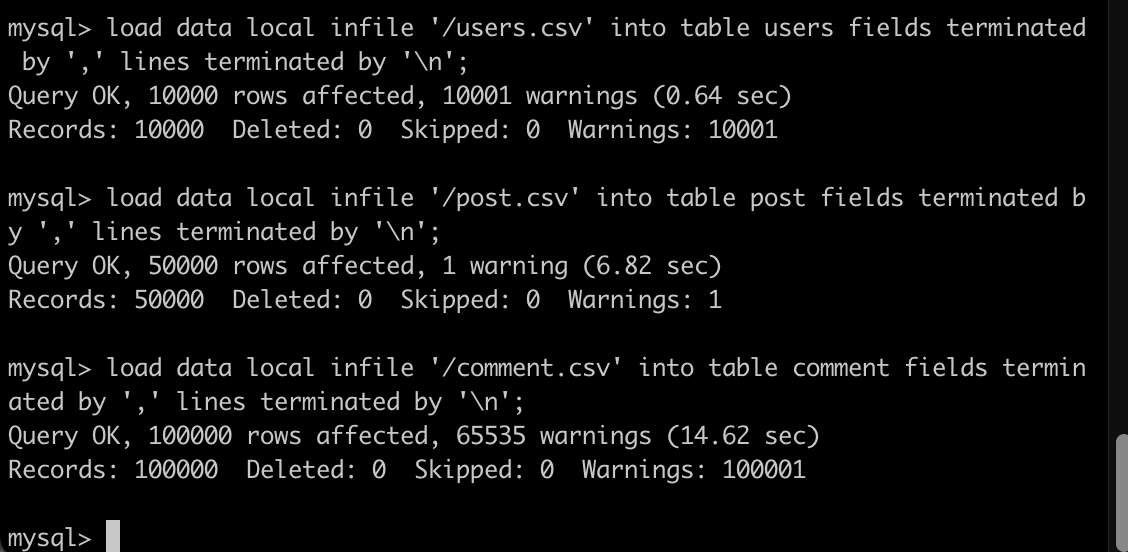
하루 온종일 삽질했는데 글 쓰고 나니 짧네요.
미래에도 똑같은 문제로 고생할 나를 위해 이 글을 바칩니다.
2022-08-31 추가:
aws rds mysql에 데이터를 넣고 있습니다.
csv파일을 어떻게 옮기지 고민하다가
https://ttoj.github.io/study/db/intro/MySQL-csv-import/
[MySQL] csv 파일 import 하는 방법 모음
MySQL에 대용량 csv 파일을 import하는 방법을 알아보자.
ttoj.github.io
이 글을 보고 해결했습니다
mysql -u admin -p -h <엔드포인트> --local-infile 로 접속해서
load data 할 때 로컬 pc의 절대경로 csv파일을 넣어주면 잘 된다
아래처럼
LOAD DATA LOCAL INFILE "C:\\Users\\ckdal\\GitHub\\pythonBOJ\\post.csv" into table spring_cafe.post fields terminated by ',' lines terminated by '\n'
'기타' 카테고리의 다른 글
| [극한의 자동화] Ngrinder + AWS + Github action + springboot (3) | 2022.09.14 |
|---|---|
| nGrinder + Springboot 부하 테스트 튜토리얼 (8) | 2022.08.27 |
| [CI/CD] github action 맛보기 기록 (1) | 2022.06.28 |
| [대규모 시스템] 대용량 데이터 처리의 어려움 (2) | 2022.06.21 |
| 인프런 HTTP 강의 공부기록 (0) | 2022.03.01 |